

Comme annoncé précédemment, un partenariat avec la coopérative des Librairies indépendantes du Québec (leslibraires.ca) offre des opportunités de mise en valeur les données issues de l’application TAMIS. Ce partenariat prend une forme concrète avec le déploiement aujourd’hui du Robot lecteur, une interface de recherche et de navigation dans les entités tirées des livres. Le Robot lecteur est présenté avec plus de détails sur leslibraires.ca!
Partenariat avec la coopérative des Librairies indépendantes du Québec (leslibraires.ca), et état des lieux en référencement web du livre
Nous avons annoncé il y a quelques mois une collaboration avec la coopérative des Librairies indépendantes du Québec (LIQ), qui opère le site leslibraires.ca. Cette collaboration se concrétise notamment par deux projets: un état des lieux du référencement web du livre, et une opportunité pour les contenus traités dans TAMIS de bénéficier de nouvelles approches permettant d’en augmenter la découvrabilité dans l’écosystème des LIQ. Une vidéo de de la présentation de l’état des lieux, ainsi que des informations supplémentaires sur les opportunités pour les éditeurs, sont disponibles sur la page dédiée au partenariat.
Nouveautés 2021 dans TAMIS
L’année 2021 s’est terminée récemment et c’est le moment pour le bilan des nouveautés dans la plateforme TAMIS. Cette année a été marquée par le souhait de sortir des sentiers battus de l’utilisation des métadonnées descriptives de livres.
Ce souhait s’est exprimé sur deux axes de développement. Le premier consiste à aller encore plus loin dans l’exploration des données générées par les intelligences artificielles de TAMIS. Le deuxième porte quant à lui sur la création d’outils concrets qui vont permettre aux livres d’être plus présents et découvrables dans le web de façon de générale, et pas seulement dans les canaux traditionnels.
Au menu (et en résumé si vous n’avez pas le temps de lire le reste!) :
- l’exploration des entités présentes dans les livres ;
- les liens entre les livres et Wikidata ;
- un outil pour générer des données structurées utilisant le vocabulaire Schema.org, au format JSON-LD ;
- des partenariats pour améliorer la visibilité des livres présents dans TAMIS avec l’Institut canadien de Québec et la coopérative des Librairies indépendantes du Québec.
Explorer grâce aux entités
Nous avons abordé le concept des entités en juin dernier. Pour rappel, une entité est une référence explicite, dans un texte, à un concept ou une chose. Par exemple, dans le passage « Voir Montmartre peut être considéré comme de la chance. Pas pour moi, car je suis né à Paris » (tiré de Confidences à l’aveugle de Alain Raimbault, aux Éditions Hurtubise), « Montmartre », « chance » et « Paris » sont des entités.
Lorsqu’elles sont bien identifiées, les entités sont utiles, parce qu’elles permettent de faire des liens.
D’abord, des liens entre les oeuvres, par exemple en trouvant qu’un personnage d’un autre bouquin, complètement distinct du premier, semble répondre au passage cité précédemment : « As-tu vu ça, Paul ? C’est ben beau Montmartre… » (Les héritiers du fleuve, tome 4, de Louise-Tremblay d’Essiambre, chez Saint-Jean Éditeur).
Mais également, des liens entre une oeuvre et le web (plus de détails un peu plus bas !).
TAMIS offre donc désormais plusieurs outils associés aux entités.
Dans la page d’un texte, des boutons permettent d’accéder à des écrans affichant les entités identifiées, à la section « Entités».
Le premier bouton permet d’accéder à une page qui contient l’ensemble des entités mentionnées dans un texte:

La liste est énorme! Elle présente en effet l’exhaustivité des entités mentionnées dans le texte. Le deuxième bouton de la page des textes, nommé «Les essentiels», permet quant à lui d’accéder à une liste des entités les plus fréquemment mentionnées, et regroupées selon qu’il s’agisse d’un lieu, d’une personne, ou d’autre chose.
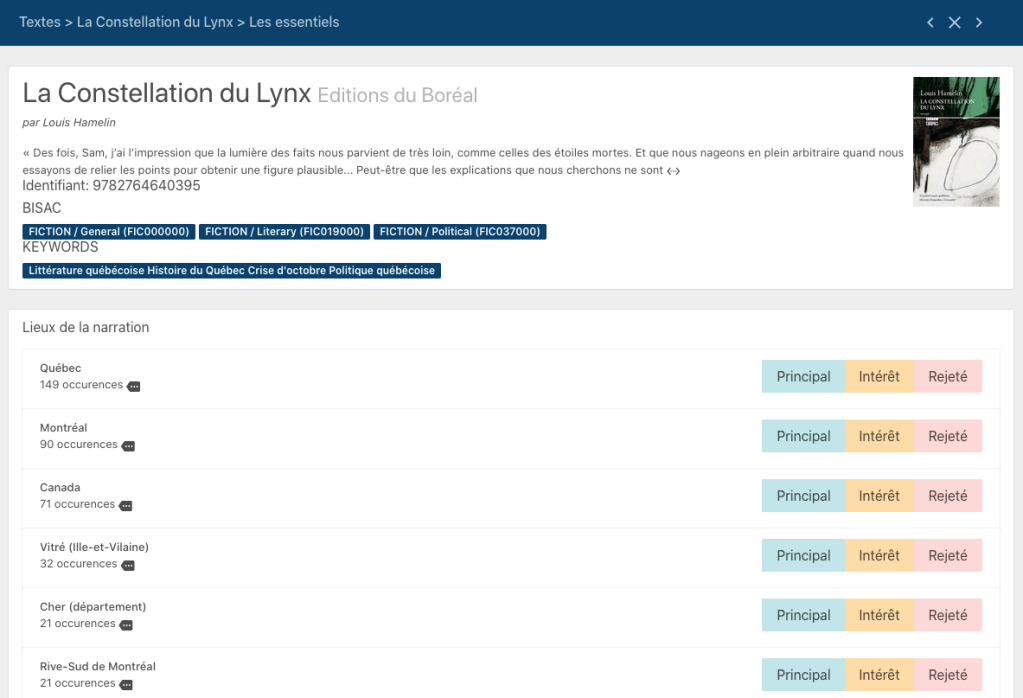
Ces deux listes demandent quelques secondes d’affichages… vous constaterez qu’il y a plusieurs entités dans un livre !
Dans les deux cas, un clic sur l’icône de l’étiquette permet d’arriver à une page qui donne de l’information sur l’entité en question, dans le contexte d’un livre, notamment des extraits du texte qui la mentionnent :
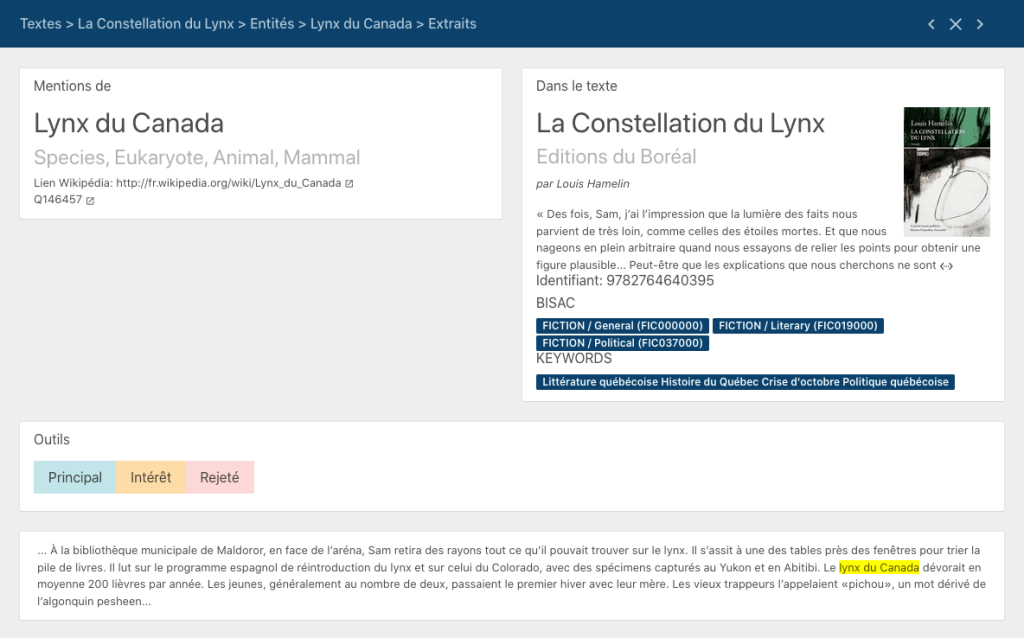
Cette page contient également un lien vers l’entrée correspondant à l’entité dans Wikipédia et Wikidata, et des boutons qui permettent d’indiquer si l’entité en question représente le sujet principal du texte, un sujet d’intérêt (ou un sujet rejeté, parce qu’il n’est pas pertinent ou qu’il s’agit d’une erreur d’identification de l’IA).
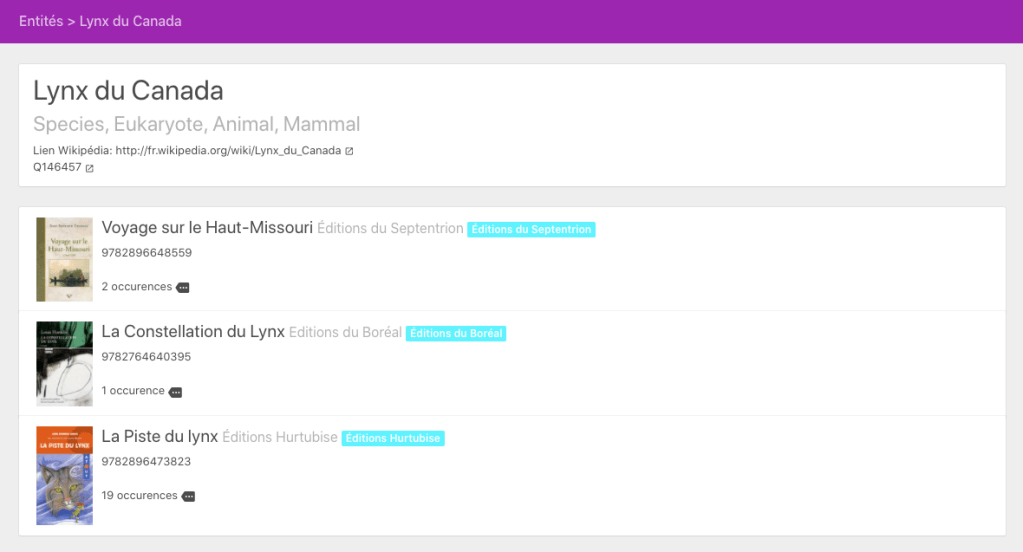
Un lien permet de naviguer pour voir les autres livres mentionnant l’entité :
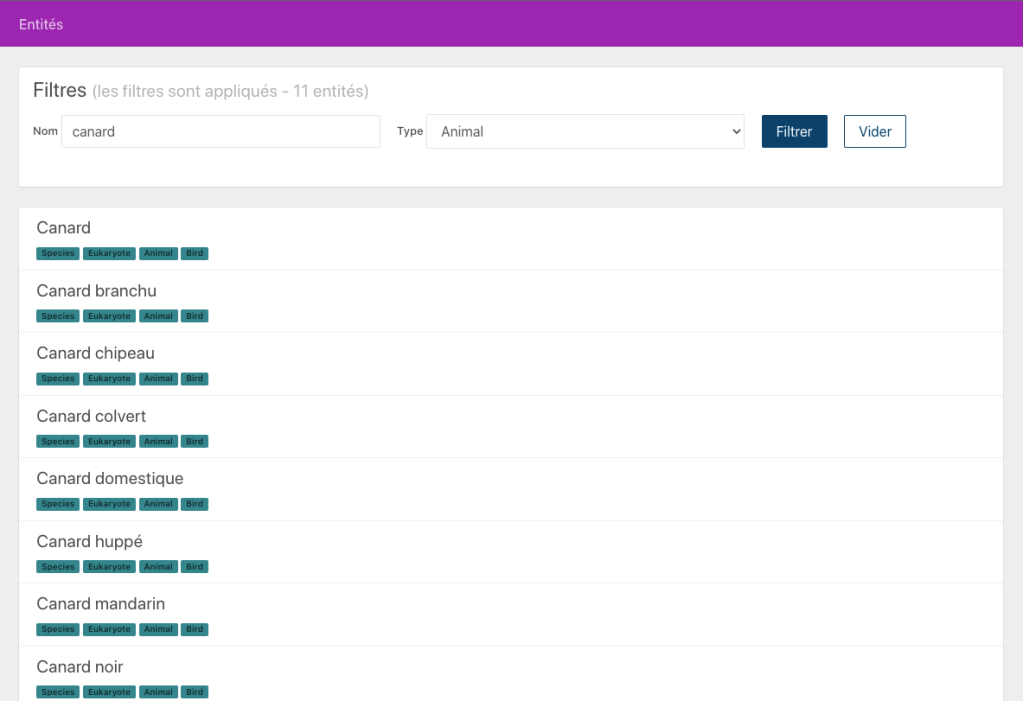
Un outil de navigation et de recherche est également disponible dans le menu de gauche. Il permet de faire des recherches par nom d’entité, ou de lister toutes les entités associées à une catégorie en particulier:
Et les autres entités associées aux oeuvres ?
Au-delà du contenu du texte, d’autres entités très importantes sont associées à une oeuvre, notamment l’auteur ou l’autrice, les autres personnes ayant contribué (pour la traduction, les illustrations, la préface…), le lieu de publication, les éditions et leurs ISBN, la maison d’édition…
TAMIS contient désormais, dans la page d’un texte, des sections qui présentent les contributeurs, ou les éditions. Dans la page dédiée à chacune de ces entrées, par exemple un auteur, on peut même créer un lien vers l’entrée correspondante dans Wikidata sans avoir à quitter TAMIS, par une simple recherche, comme illustrée dans la courte vidéo suivante :
Des outils pour exploiter les liens et rendre les livres plus découvrables
Au-delà de l’aspect ludique d’explorer les oeuvres à travers les entités qui y sont mentionnées (et croyez-nous, c’est vraiment fascinant !), à quoi cela sert-il d’identifier les entités importantes d’un texte ? La réponse est dans les liens que cela permet de créer entre une oeuvre et le reste du web.
Le web est organisé autour des liens entre les pages, les sites web, les personnes, et de plus en plus, entre les entités. Les moteurs de recherche, notamment Google, s’intéressent de plus en plus à identifier les entités qui font partie des requêtes des utilisateurs. Et la présence de liens entre des pages est un signal important pour leur référencement.
Utiliser le nom des entités à la façon de mots-clés, dans des descriptifs de livres à travers les métadonnées traditionnelles, c’est bien.
Exploiter les liens entre le livre et des entités existantes sur le web, c’est mieux !
Il y a plusieurs stratégies pour le web. Deux d’entre elles ont été ajoutées dans TAMIS au cours des derniers mois :
- les données structurées pour Google et les autres moteurs de recherche ;
- la création de références dans Wikidata.
Les données structurées pour Google et les autres moteurs de recherche
TAMIS permet de générer une description d’un livre au format JSON-LD, en utilisant le vocabulaire Schema.org. Il vous suffit d’utiliser le bouton « Schema.org » de la boîte d’outils « Connexions » de la page d’un texte pour obtenir le résultat suivant:
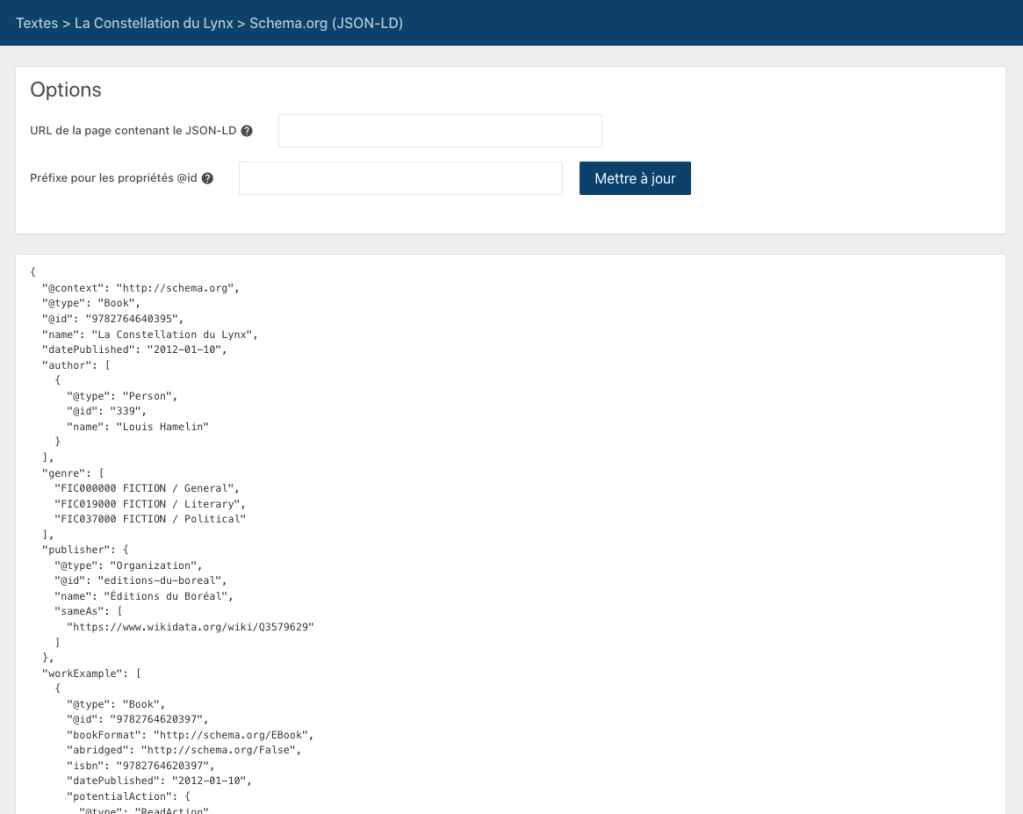
Pour simplifier, on peut dire que JSON-LD et Schema.org sont au web ce qu’ONIX est à la chaîne de valeur du livre ou MARC aux bibliothèques : c’est un standard technique pour décrire les livres.
Le code au format JSON-LD peut par exemple être intégré dans une page web qui décrit le livre pour faciliter la compréhension, par un moteur de recherche, des données relatives à ce livre. Par ailleurs, le code généré contient des références aux entités préalablement sélectionnées comme sujet principal ou d’intérêt pour un texte, de façon à rendre explicites les liens entre l’oeuvre et ces entités aux yeux du moteur de recherche. Il contient également différentes informations tirées du fichier ONIX original, comme les mots-clés, les catégories BISAC, etc.
💡 Vous souhaitez intégrer des données structurées à votre site web ? Les modèles générés par TAMIS ne seront probablement pas suffisants pour que votre intégrateur web le fasse. Contactez-nous pour avoir quelques conseils (ou un coup de main) avant d’ouvrir ce chantier !
La création de références dans Wikidata
TAMIS dispose désormais d’outils qui permettent de déposer des données dans Wikidata. Ainsi, pour chaque livre, une page permet de réviser les liens entre les données disponibles dans TAMIS, et les entités existantes (ou pas dans Wikidata). Cet outil s’appuie sur les propriétés et le modèle proposés par le Wikiprojet Livres, qui distingue les informations sur l’oeuvre, et celles sur ses éditions.
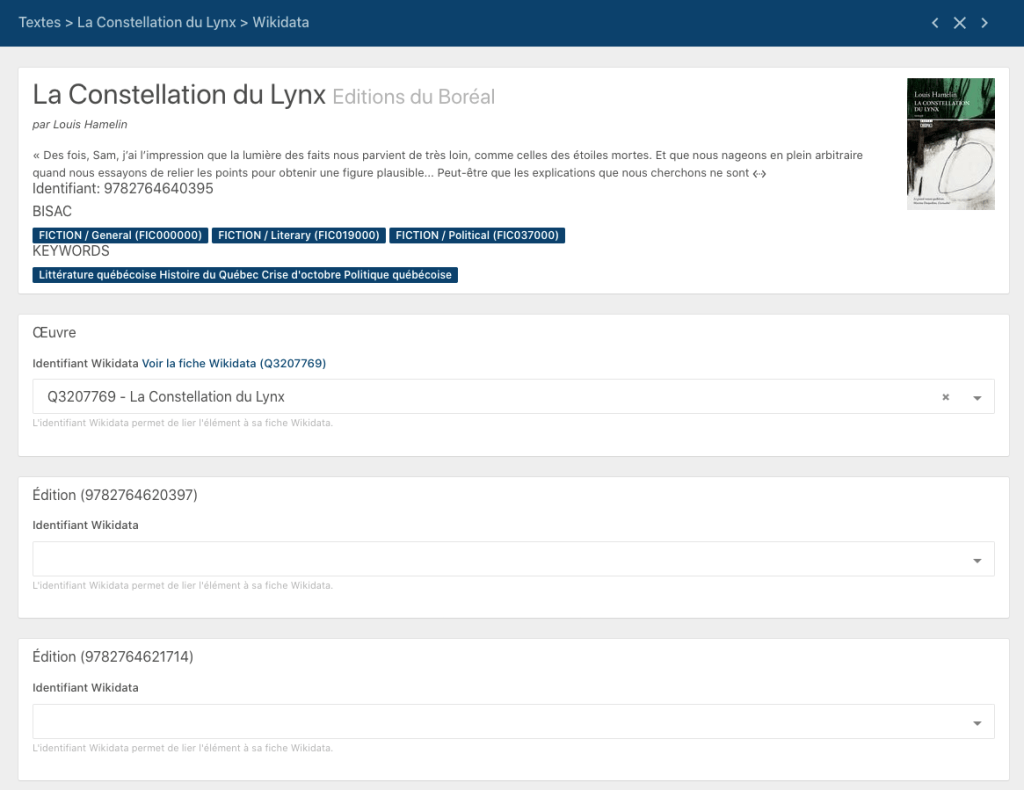
L’outil très simple permet de réviser et confirmer la correspondance entre les données dans TAMIS, et des items dans Wikidata. Un simple clic va créer de nouveaux items dans Wikidata, noter leurs références dans TAMIS (pour faciliter d’éventuelles mises à jour), ou mettre à jour des items existants en ajoutant des propriétés supplémentaires.
TAMIS tire évidemment profit de sa connaissance du contenu des livres pour enrichir les fiches Wikidata de propriétés comme le lieu de l’action (P840), les personnages (P674) et les sujets principaux (P921).
À noter, TAMIS ne dépose aucune donnée sans qu’un opérateur humain ne les ait révisées, et se soit assuré que l’opération ne créera pas de conflits ou de doublons dans Wikidata.
💡 Le dépôt de données sur Wikidata demande la configuration d’un compte ayant accès en écriture, par API, sans blocage d’adresses IP, à Wikidata (typiquement un compte de «bot»). TAMIS ne dispose pas d’un tel compte qui puisse être utilisé par tous. Veuillez nous contacter pour configurer votre compte de «bot» dans TAMIS.
Quoi d’autre ?
La dernière année a également été l’occasion de faire en sorte que TAMIS fonctionne en anglais. En plus de la (relativement) simple opération de traduire l’interface, la complexité était évidemment associée au besoin de traiter du contenu dans une autre langue, et donc de s’assurer que les outils de traitement du langage naturel fonctionnent en anglais. C’est désormais le cas pour tous les outils, à l’exception de l’outil de suggestion de codes BISAC.
Pour la prochaine année, nous espérons voir un déploiement à plus grande échelle des nouveaux outils présentés précédemment. Nous travaillons depuis plusieurs mois avec deux partenaires qui contribuent à la découverte et de visibilité des livres, et qui le feront de façon innovante à partir des données disponibles dans TAMIS. En effet, l’Institut canadien de Québec (Maison de la littérature, festival Québec en toutes lettres) et la coopérative des Librairies indépendantes du Québec (leslibraires.ca, quialu.ca et revue Les libraires), utiliseront les données de TAMIS dans leurs activités respectives de mise en valeur des livres et de la littérature.
C’est d’ailleurs les partenariats avec ces deux organisations qui ont rendu possibles certaines des améliorations présentées précédemment. Nous en profitons également pour souligner les contributions du Conseil des arts du Canada, partenaire de la coopérative des Librairies indépendantes du Québec, et le Conseil des arts et des lettres du Québec, partenaire de l’Institut canadien de Québec.
À retenir…
Si vous êtes un éditeur qui utilise déjà TAMIS, nous vous donnerons plus de détails bientôt. Vous pourrez évidemment décider si vous souhaitez ou pas que vos livres puissent être inclus dans ces projets ! N’hésitez pas à nous contacter dès maintenant si vous souhaitez manifester votre intérêt plus rapidement ou si vous avez des questions. Vous pouvez également ouvrir la discussion avec votre contact à la coopérative des Librairies indépendantes du Québec.
Si vous êtes un éditeur qui n’utilise pas déjà TAMIS et qui voulez en savoir plus, ou éventuellement vous joindre à ces projets, n’hésitez-pas à nous contacter !
Nouvelle étape: l’enrichissement des données (1)
Le développement de Tamis est entré récemment dans une nouvelle phase, encore plus excitante que les précédentes.
En effet, après avoir appris à utiliser divers algorithmes pour analyser les couvertures et les textes de livres et en extraire divers éléments utiles pour les décrire, nous avons commencé à utiliser également ces données dans le but de permettre de nouveaux types de recherche et d’analyse de l’ensemble des livres qui ont été mis à notre disposition.
Nous souhaitons, par exemple, être en mesure d’identifier tous les livres dont l’action se déroule à proximité de la Rivière Saint-Charles — et même les passages précis où l’action s’y déroule! Autre exemple: identifier les livres écrits par des femmes qui sont nées dans la région de Québec avant 1950. Ou encore les livres publiés par des maisons d’édition de Québec dont l’auteur, ou l’autrice, est née à l’étranger.
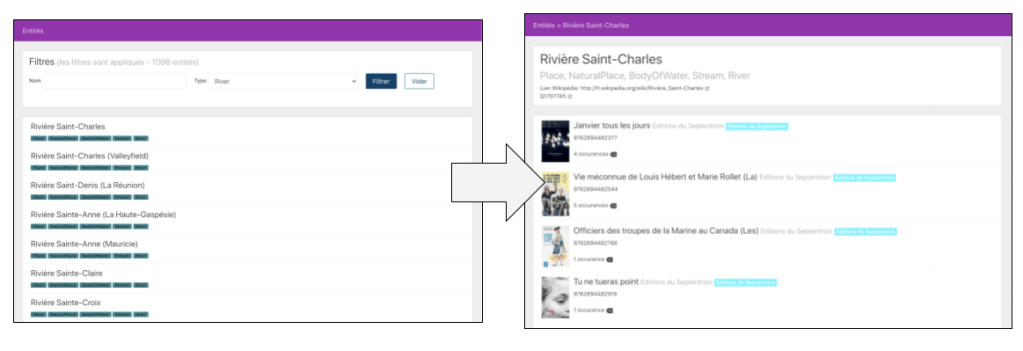
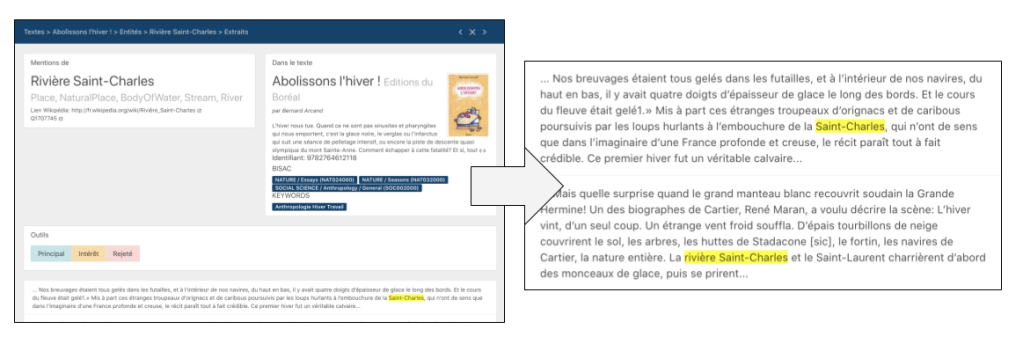
Nous voulons évidemment pouvoir faire aussi l’inverse: partir d’un livre et explorer, visuellement, sur une carte, tous les lieux qui sont évoqués; ou les événements historiques auxquels il est fait référence; ou encore les aliments, les groupes musicaux, les planètes, les éléments chimiques, etc.
Pour arriver à répondre à ces questions, nous avons besoin de pouvoir lier les données que les algorithmes de Tamis nous ont permis d’extraire avec des données qui se trouvent dans d’autres bases de données — et en tout premier lieu, avec les données que Wikidata met à notre disposition.
Mais avant d’aller plus loin… prenons le temps d’explorer, sommairement, ce qu’est Wikidata et pourquoi cette base de données est en train de prendre une importance croissante dans l’organisation de l’information sur le Web (et même beaucoup plus largement).
Wikidata? Vous voulez dire Wikipédia?
Tout le monde connaît maintenant Wikipédia — une des projets les plus ambitieux de l’ère numérique: une encyclopédie universelle, multilingue, à laquelle tout le monde peut contribuer. Il y a vingt ans, bien des gens disaient que « ça ne pourrait pas marcher, parce que si tout le monde pouvait modifier le contenu, ce serait forcément un peu n’importe quoi ». Pourtant, la suite montre que ça fonctionne, et que Wikipédia est devenue une source d’information de qualité, fiable… et de plus en plus indispensable!
Wikidata, c’est un peu la même chose, mais à l’intention des machines: c’est une base de données de référence sur tous les sujets, que tout le monde peut modifier, et où l’information est rassemblée de manière à pouvoir être utilisée dans le cadre de processus automatisés (algorithmes) plutôt que pour être consultée par des êtres humains. Pas de mise en page, pas de phrases complètes, juste des informations factuelles, présentées de façon normalisée et organisée de façon structurée.
Wikidata indique, par exemple, que Jean-Paul L’Allier est un être humain (rien d’évident là pour un algorithme 0 il est donc pertinent de le préciser!), de sexe masculin, qu’il a un lieu de naissance, quelles ont été ses principales occupations qu’il a exercées, les reconnaissances qui lui ont été accordées, etc. — ainsi qu’une série d’identifiants qui permettent d’aller chercher de l’information complémentaire à son sujet dans d’autres sources de données.
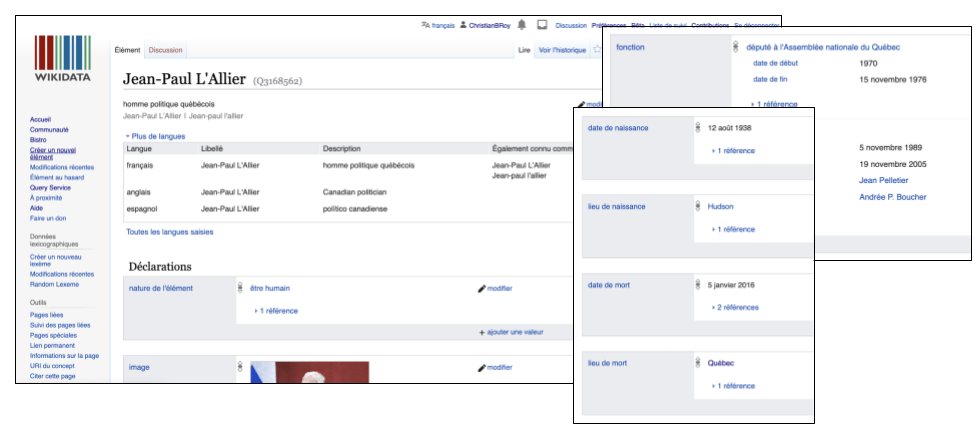
C’est comme ça que si on possède une base de données d’auteurs et d’autrices, par exemple, et qu’on a pris la peine d’y noter, pour chacun, son identifiant dans Wikidata (qu’on peut voir dans le haut de la page, sur Wikidata: Q3168562, dans le cas de Jean-Paul L’Allier), on pourra assez facilement programmer un petit algorithme pour aller chercher dans Wikidata une foule d’autres informations sur chacun des auteurs et des autrices afin de compléter notre base de données.
La magie des liens
Mais là où la magie opère vraiment, c’est que l’information dans Wikidata est organisée de façon sémantique, toutes les entités sont liées les unes avec les autres. Ce qui permet d’aller beaucoup plus loin que de simplement additionner des informations d’une base de données à l’autre. Parce que la latitude et la longitude d’un lieu sont associées à une ville, à une région, un pays; parce qu’une rivière est associée à ses affluents; parce que les années sont associées à une période historique, etc.
C’est en suivant ces liens d’une donnée à l’autre qu’on peut savoir qu’un livre qui fait référence au Pont Drouin peut aussi être associé à la Rivière Saint-Charles; qu’un récit qui fait référence à l’usine WhiteBirch, à Québec, est non seulement près de la même rivière, mais qu’il se déroule forcément entre telle année et telle année, etc.
Concrètement, en associant un lieu de naissance à des auteurs et autrice dans Wikidata, et sachant que ces lieux sont à leur tour associés à des régions, auxquelles sont associées des coordonnées géographiques… il devient possible d’identifier tous les auteurs et les autrices sont nées au nord du 45e parallèle, par exemple. Ou de savoir combien d’auteurs d’une maison d’édition ont aussi travaillé à la réalisation d’un film, en s’appuyant sur les identifiants qui relient Wikidata à IMDB, une base de données spécialisée sur le cinéma.
Ce n’est évidemment pas sans raison que Google, Microsoft, Facebook, Amazon, etc. utilisent abondamment les données de Wikidata. C’est parce qu’ils croient qu’elles sont utiles pour rejoindre plus efficacement leurs usagers, pour leur offrir de meilleurs résultats de recherches et de meilleures recommandations.
Des opportunités pour améliorer la commercialisation du livre
Cela révèle deux opportunités pour le monde du livre: apprendre à utiliser nous aussi les données ouvertes et liées (comme celles de Wikidata) et enrichir ces données de celles qui concernent les livres publiés ici, pour les rendre plus facilement découvrables, dans toutes sortes de contextes.
Que ce soit pour répondre à des objectifs très précis, comme améliorer le référencement d’un livre sur un sujet pointu, ou tout «simplement» pour faire en sorte qu’Alexa, Siri et leurs collègues connaissent la littérature d’ici, il est essentiel de saisir ces opportunités.
C’est à ce double défi que nous nous attaquons maintenant avec Tamis. Nous le faisons en collaboration avec l’Institut canadien de Québec, dans le cadre d’un projet qui s’inscrit dans la perspective de Québec, ville de littérature de l’UNESCO. Un projet qui est soutenu par le programme Exploration et déploiement numérique du Conseil des Arts et des Lettres du Québec (CALQ).
Avant de commencer le travail, nous avons tenté de tracer un premier portrait préliminaire de la présence des auteurs et autrices et romans de Québec (et du Québec) sur Wikidata.
Ce sera le sujet du prochain texte.
Des nouvelles de TAMIS!
Ça fait plusieurs mois que nous n’avions pas donné des nouvelles du projet TAMIS. Ça ne signifie toutefois pas que l’outil n’évoluait pas pendant ce temps ! Nous sommes heureux d’annoncer quatre nouveautés maintenant disponibles dans la console TAMIS (et le retour d’un outil momentanément désactivé !).
Notons que ces nouveautés ont été rendues possibles grâce à la participation de la Société de développement des entreprises culturelles (SODEC).
Documentation en ligne
Le fonctionnement de la console n’est pas très compliqué, mais il est toujours utile d’avoir de la documentation lors de l’utilisation d’une nouvelle application ! Nous avons donc produit une documentation en ligne qui explique l’utilisation de la console. La documentation est volontairement brève : quelques minutes de lecture devraient suffire pour comprendre les outils disponibles. Elle est accessible depuis l’item « Aide et légal » du menu déroulant associé à l’utilisateur connecté (en haut à gauche de l’écran).

Export des textes vers un entrepôt numérique
La console TAMIS offre désormais deux outils pour faciliter la transmission des métadonnées enrichies vers l’Entrepôt numérique ANEL-De Marque. Les deux outils sont disponibles par le menu d’outils de la section Textes. Le premier permet de générer un rapport Excel dans un format compatible avec l’entrepôt numérique ; ce rapport peut par la suite y être importé. Le second transfère les données directement dans un compte de l’entrepôt numérique.
Plus d’information est disponible dans la section Exporter les textes de la documentation.
Import de textes de différentes sources
Auparavant, seuls des livres disponibles dans un entrepôt numérique, aux formats EPUB ou PDF, disposant de métadonnées au format ONIX 3.0, et identifiés par un ISBN, pouvaient être traités par TAMIS. Il est désormais possible d’importer n’importe quel texte, avec ou sans métadonnées. Le format texte brut est supporté, en plus du PDF et de l’EPUB.
Plus d’information est disponible dans la section Ajouter un texte de la documentation.
Conseils et bonnes pratiques
La console affiche désormais quelques conseils et bonnes pratiques tirées de différentes sources (comme le guide des services de diffusion de De Marque, ou la documentation en ligne de BISAC sur le site de BISG). Ces conseils sont personnalisés pour chaque titre, en fonction des métadonnées associées au titre au moment de son importation, en plus de celles qui sont choisies suite aux suggestions de TAMIS.

Tous les conseils s’affichent dans la fiche d’un texte. Des conseils spécifiques aux mots-clés ou aux codes BISAC s’affichent également dans les écrans dédiés à ces deux types d’enrichissements.
C’est tout ?
Non ! L’outil de suggestion de classifications BISAC, qui était indisponible depuis quelques mois, est de nouveau accessible. Si vous êtes curieux et souhaitez connaître les enjeux techniques (et économiques !) qui expliquent cet hiatus, lisez notre texte sur la nouvelle itération sur notre module de classification.
Une nouvelle technologie de classification pour l’outil de suggestions de code BISAC de TAMIS
Il y a quelques mois, nous avons dû retirer l’outil de suggestion de classifications BISAC de la console TAMIS. Nous avons en effet fait face à un problème : le modèle d’affaires de la technologie de classification que nous utilisions a changé… rendant le coût de traitement de chaque livre trop élevé pour qu’il soit possible de continuer à l’utiliser. Comme nous l’annoncions récemment, le problème est maintenant réglé. Pour nos lecteurs plus curieux qui veulent mieux comprendre comment ça se passe « sous le capot », voici plus d’information sur ce qui s’est passé.
En rappel : comment fonctionnait le classificateur
Nous avons déjà expliqué comment fonctionne notre classificateur BISAC. Il s’agit en fait d’un assemblage de plusieurs dizaines de classificateurs « spécialisés » dans différentes « branches » de l’arborescence BISAC. C’était notre façon d’utiliser des solutions de classification disponibles sur le marché tout en tenant compte de la complexité inhérente au domaine du livre (des textes très longs, des catégories très nombreuses et hiérarchisées, et des textes qui peuvent appartenir à plusieurs catégories).
C’est la technologie générique utilisée, Auto ML de Google Cloud Natural Language qui nous a posé problème : son coût d’utilisation, dans notre contexte, a littéralement explosé.
La solution : créer notre propre classificateur générique
On le savait par les travaux que nous avions réalisés précédemment : il n’y a pas sur le marché d’alternative intéressante à la solution que nous avions retenue. Face à ce constat, nous avons entrepris de développer une solution de remplacement.
C’est évidemment plus facile à dire qu’à faire ! Et c’est ici qu’entre en jeu l’équipe de Baseline, une coopérative de travailleurs formée d’étudiants gradués provenant de sphères variées du milieu académique telles que l’informatique, les mathématiques, la physique, l’actuariat et la finance. Baseline est spécialisée, entre autres, en apprentissage automatique et en traitement automatique du langage naturel.
L’équipe de Baseline a rapidement compris nos enjeux et s’est affairée à développer une solution de remplacement qui réponde à plusieurs objectifs :
- s’intégrer harmonieusement dans l’architecture technique de TAMIS ;
- pouvoir être exploitée à des coûts raisonnables (autant pour la phase d’entraînement, que pour l’étape de classification) ;
- avoir des performances au moins aussi bonnes que la solution précédente.
Nous avons choisi de travailler de façon itérative. Une première itération a permis d’établir une première solution « de base », qui répondait au premier objectif et permettait de confirmer que le second objectif était atteignable. Par la suite, d’autres itérations ont permis de travailler sur le troisième objectif, celui de la précision de l’outil.
À cette étape, l’équipe de Baseline a testé plusieurs solutions, dont les principales différences sont la source des vecteurs de mots utilisés pour entraîner la solution. Nous avons testé des vecteurs de mots issus exclusivement de notre corpus, ainsi que d’autres vecteurs disponibles sur le web, dont des variantes du célèbre BERT (célèbre auprès d’un public un peu geek, on l’avoue). Puis, pour certains vecteurs, nous avons testé différentes combinaisons d’hyperparamètres (des choix de configuration sur la façon de procéder à l’apprentissage). Certaines combinaisons de vecteurs ou d’hyperparamètres ont été écartées parce qu’elles n’offraient pas de bonnes performances, ou parce qu’elles demandaient trop de ressources (mémoire, capacité des processeurs) pour respecter les contraintes de coûts d’exploitation.
Pour évaluer la performance de chaque variante, nous avons utilisé les techniques classiques : séparer le jeu de données pour réserver certaines données à des fins de tests, et observer les indicateurs de précision et de rappel (et leur moyenne pondérée, le « F1-score »).
Au final, il n’a pas été possible de trouver une combinaison qui performait bien sur tous nos classificateurs. Nous avons donc retenu des combinaisons de vecteurs et d’hyperparamètres différents pour chaque classificateur. La performance moyenne (encore une fois mesurée par la précision et le rappel) du système est légèrement supérieure à ce que nous obtenions avec la solution de Google. Il y a toutefois des écarts plus importants (positifs ou négatifs) pour certaines catégories. Quant aux coûts d’utilisation, ils sont revenus à des niveaux raisonnables.
Ça semble compliqué… 🤔
Ce l’est ! Classifier un livre demande de combiner habilement les résultats de plusieurs « sous classificateurs », interrogés en cascade en fonction du résultat du précédent, qui eux-mêmes sont tous issus d’un processus d’optimisation complexe et exploitent chacun une approche différente d’apprentissage ! 🤯
Et c’est sans compter que la préparation des classificateurs, le processus d’apprentissage, demande des heures, voir des jours…
Mais ça fonctionne !
Le résultat n’est évidemment pas parfait, mais nous pensons qu’il simplifiera la vie à ceux et celles qui veulent diversifier les classifications BISAC utilisées. Et en théorie, le résultat s’améliorera au fur et à mesure qu’il y aura plus de titres dans TAMIS. En effet, en science des données en général, et en particulier dans le cas qui nous occupe, la quantité de données d’entraînement est autant, sinon plus, importante que le choix des algorithmes. De plus, la solution constituera une base solide pour d’autres applications associées à la classification des textes par TAMIS…
Une nouvelle approche pour suggérer des catégories BISAC automatiquement
Nous avons déjà expliqué pourquoi nous nous intéressons aux systèmes de classification dans un texte précédent. Et nous avons expliqué avoir obtenu des résultats intéressants, mais insuffisamment précis pour être utiles.
Après de nouveaux travaux, nous pensons être arrivés à une solution plus satisfaisante!
Ce texte explique comme nous y sommes arrivés et présente quelques résultats.
Rappel sur les classificateurs de textes
Pour comprendre notre démarche, il faut se rappeler comme fonctionnent les classificateurs de textes disponibles sur le marché. Sans s’attarder aux détails techniques et aux nuances, il faut comprendre que les classificateurs de textes en général «apprennent» à classifier à partir d’exemples. On fournit à un algorithme des milliers d’échantillons de textes, accompagnés de la catégorie à laquelle appartient le texte. L’algorithme «s’entraîne» à reconnaître de nouveaux textes, similaires à ceux des échantillons, et prédire dans quelle catégorie il doit le placer.
On peut illustrer le processus comme ceci:

C’est à l’algorithme de déterminer quels facteurs font qu’un texte doit être associé à telle ou telle catégorie. Il le fait essentiellement en établissant des corrélations statistiques entre des mots et des combinaisons de mots, et des catégories. Par exemple, les textes qui contiennent souvent «Bas Canada» et «Haut Canada» sont associés à la catégorie histoire (alors que «Canada» seul est peut être neutre et n’influence pas la catégorie). Ceux qui contiennent «Trudeau» et «Lévesque» sont plus susceptibles de traiter de politique; «influenza» et «appendice» sont des indicateurs de textes en médecine; etc.
Avec de très longs textes, les centaines de milliers de mots de la langue française, et près de 5000 catégories BISAC, on a du mal à imaginer la complexité des calculs statistiques nécessaires pour faire de bons classificateurs.
Les problèmes rencontrés précédemment
Les algorithmes de classification décrits précédemment sont évidemment influencés par la qualité et la quantité des données utilisées pour les entraîner.
Par exemple, si on ne donne en entraînement aucun texte dans la catégorie des biographies, l’algorithme ne pourra jamais identifier des biographies.
De la même façon, si on lui donne en grande majorité des textes classés comme une fiction (sans plus de précision), il fera en grande majorité des prédictions dans la catégorie fiction (…sans plus de précision!).
Notre première version de classificateur BISAC était affectée par ce problème. Les classifications dont nous disposons dans nos jeux de données ne sont pas nécessairement représentatives de ce qu’on veut voir dans nos résultats. On sait qu’on a beaucoup trop de livres classés dans la catégorie BISAC FIC000000 (la plus générale en fiction), on cherche à générer des classifications plus précises et plus riches.
Comment résoudre ce problème? Une approche est d’augmenter le nombre de textes disponibles pour l’entraînement, si on émet l’hypothèse que les nouveaux textes amènent de la diversité dans les catégories. Nous avons augmenté d’environ 25% le nombre de titres disponibles pour l’entraînement dans la nouvelle version de notre classificateur BISAC (essentiellement en traitant les fichiers PDF disponibles; nous avions utilisé les EPUB seulement dans la première version).
Un autre problème de la première version de notre classificateur était qu’il distinguait mal les textes de fiction des textes documentaires. Pour reprendre un des exemples précédents, un roman historique pourrait utiliser les termes «Bas Canada» et «Haut Canada» autant qu’un essai sur la politique à l’époque. Comme le classificateur ne connaît pas le système de classification, qui est hiérarchique (on distingue d’abord la fiction d’autres thèmes, puis à l’intérieur de chaque thème on a des sous-thèmes), il est très difficile pour lui de traiter ces cas.
Une nouvelle approche: on remplace le classificateur par des dizaines de classificateurs qui travaillent en équipe!
Nos travaux sur la nouvelle version du classificateur ont donc été réalisés pour atteindre deux objectifs:
- trouver une façon «d’aider» l’algorithme à comprendre la hiérarchie du système de classification ;
- ajuster la quantité de textes utilisés sur l’entraînement pour éviter de «surexposer» les algorithmes à certaines catégories.
Le résultat final est que le classificateur BISAC de TAMIS est en fait constitué d’une quarantaine de classificateurs spécialisés sur certaines «branches» de la hiérarchie BISAC. Ainsi, chaque texte est d’abord passé à un premier classificateur, qui sait distinguer les textes des catégories de premier niveau pour lesquelles nous avons un nombre suffisant d’échantillons.

Pour chaque catégorie, le classificateur indique la probabilité qu’elle s’applique au texte. Notre algorithme identifie les catégories les plus probables, trouve une classificate «spécialisé» pour chaque, et répète le processus.

Une fois le processus complété, un autre algorithme assemble les résultats, en pondérant les probabilités obtenues de chaque classificateur spécialisé, et arrive à une suggestion de 3 à 5 codes BISAC. Dans certains cas, si la probabilité obtenue de tous les classificateurs est trop faible, aucune suggestion n’est faite.
Note sur la technologie de classification utilisée
Pour nos lecteurs intéressés par les questions de développement logiciel… les autres peuvent passer à la section suivante!
Lors de nos premiers tests, nous avions retenu la solution Comprehend d’AWS pour faire les classification. Cette solution était la seule qui répondait à nos besoins lors de nos travaux il y a quelques mois.
Il s’est toutefois avéré qu’elle n’était pas adaptée à notre nouveau besoin. Nous avons rencontré plusieurs contraintes lors du passage de la recherche au développement. En particulier, la limite sur le nombre de classificateurs personnalisés actifs dans un compte AWS, et le fait que les opérations de classification ne puissent être opérées qu’en lot dans un traitement différé en arrière plan. Cela rendait impossible d’utiliser notre stratégie.
Nous nous sommes alors tournés vers la solution AutoML Natural Language dans Google Cloud. Nous l’avions écartée précédemment parce que c’est un produit toujours en phase «beta» et la gestion du français n’est pas garantie. Malgré cela, les résultats sont impressionnants, et les contraintes d’utilisation sont moins grandes. Nous avons quand même été limités par un quota sur le nombre de classificateurs actifs. Aussi, bien que les opérations de classification soient réalisées en direct (et pas en traitement différé) dans des délais relativement courts, il reste que la performance n’est pas encore instantanée (il peut parfois s’écouler 3 à 5 secondes avant qu’un utilisateur de la console n’obtienne les résultats).
Les résultats
Nous observons de façon générale que les classifications proposées sont plus riches et plus diversifiées. C’était ce qu’on souhaitait.
Pour un livre sur l’histoire des patriotes, l’algorithme propose la catégorie «Political science». Pour le coffret 1967, l’éditeur avait choisi la catégorie «Fiction», l’algorithme propose «Fiction / Sagas» (c’est effectivement une saga!). Pour la biographie de Normand Brathwaite, il propose la catégorie «Performing arts».
Évidemment, comme dans la plupart de nos expériences, nous obtenons également des résultats farfelus ou impertinents. Toutefois, ces suggestions moins intéressantes sont souvent accompagnées d’une cote de «confiance» (nous y reviendrons plus loin) assez faible.
Il arrive aussi que l’algorithme ne propose que des catégories BISAC que l’éditeur avait déjà identifiées… Ça démontre sa précision, bien sûr, mais n’atteint pas nos objectifs d’enrichir les métadonnées. Cela est plus fréquent chez les éditeurs qui indiquent plusieurs catégories (et ont donc vraisemblablement déjà des métadonnées assez riches sur le plan des classifications).
L’utilisation dans la console
Concrètement, dans la console de l’éditeur, une page permet, pour chaque livre, d’obtenir les suggestions. Elle prend la forme suivante:
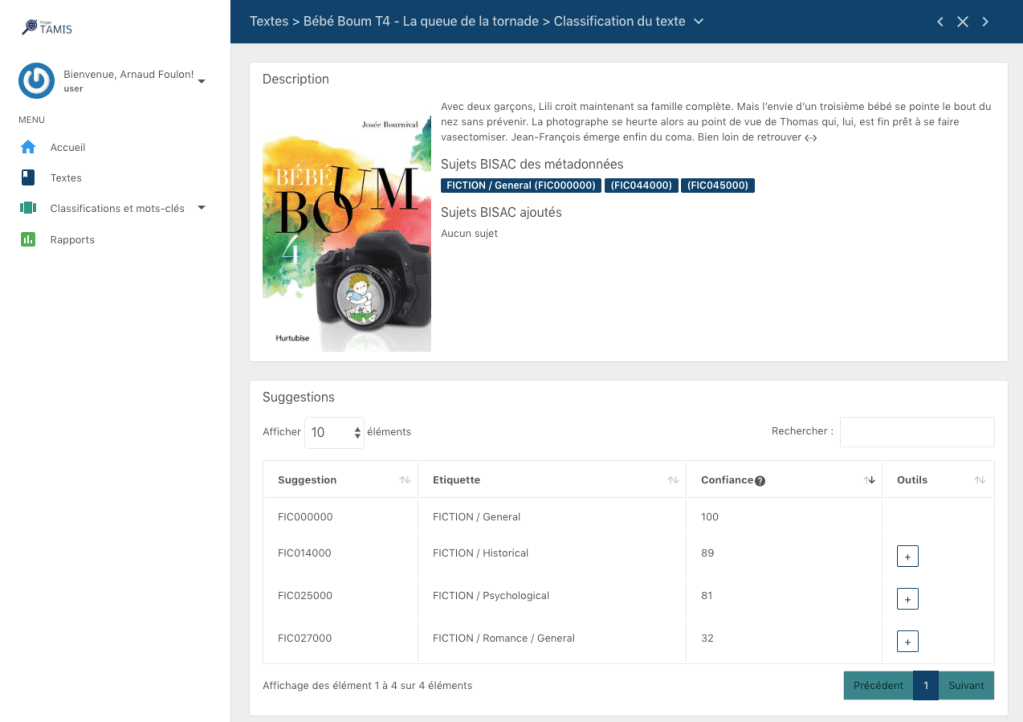
Dans le haut, on voit les métadonnées que l’éditeur avait documentées. Dans le bas, les suggestions de l’algorithme. Pour les suggestions qui n’avaient pas déjà été choisies par l’éditeur, le bouton «+» permet de confirmer et de l’ajouter aux métadonnées.
Chaque suggestion est accompagnée d’un indicateur de «confiance». Il s’agit d’un nombre, entre 0 et 100, qui donne une approximation du niveau de pertinence de la suggestion, selon l’algorithme. Un nombre élevé indique qu’il est probable que la suggestion soit pertinente.
Conclusion
Cette nouvelle version de notre classificateur BISAC n’est certe pas parfaite, mais elle résout plusieurs des problèmes de la version précédente. Son développement a présenté plusieurs défis techniques qui ne sont qu’évoqués superficiellement ici. Nous croyons que les résultats améliorés justifient les efforts.
Je cherche un livre à la couverture rouge…
Un des sujets les plus évocateurs quand on parle du projet TAMIS est celui de la couleur dominante des couvertures. L’anecdote du client en librairie qui cherche un livre dont il a oublié le titre, mais dont la couverture est rouge (ou verte ou jaune ou…) est classique. Comme TAMIS permet de générer des mots-clés décrivant les couvertures des livres, nous souhaitons également y intégrer les couleurs dominantes.
Notre première piste consistait à utiliser les mêmes API de vision par ordinateur que nous avions utilisées pour obtenir des suggestions de mots-clés. Les résultats n’étaient toutefois pas concluants sur les couleurs. Certaines API permettaient d’identifier des couleurs dominantes simplement par un code de couleur : #ED032B n’est pas très parlant pour un humain. Celle qui identifiait la couleur par un nom le faisait de façon trop sophistiquée : on s’attend à ce que les consommateurs utilisent des noms de couleurs simples (bleu, jaune, vert), pas des termes plus précis ou nuancés (saphir, ambre, émeraude).
Nous avons donc choisi, pour l’enjeu des couleurs, de ne pas utiliser d’API d’intelligence artificielle. Nous avons plutôt développé un système qui s’appuie sur une analyse des pixels composant l’image, et d’une charte qui permet d’associer des familles de codes à des noms de couleur très simples (grosso modo, les couleurs qu’un enfant de maternelle connaît!).
C’est plus simple à expliquer qu’à mettre ne place, mais ça fonctionne assez bien! La Console TAMIS, dont nous avons présenté un aperçu récemment, intégrera donc des suggestions de mots-clés associés aux couleurs dominantes de la page couverture.
Voici quelques exemples de résultats. Pour chaque image, les 5 couleurs dominantes sont présentées en ordre décroissant d’importance, selon notre algorithme. Lorsque le même nom est répété, c’est que différentes nuances de cette même couleur sont dominantes.

bleu, blanc, vert, rouge, mauve 
blanc, brun, rouge, brun, vert 
noir, rouge, jaune, brun, mauve 
rouge, blanc, noir, brun, vert 
brun, blanc, vert, rouge, jaune
Un aperçu de la console pour les éditeurs
Les travaux dans le projet TAMIS passent progressivement de l’étape de la recherche à celle des applications. La console des éditeurs prend forme. Elle permettra de voir les données générées par les intelligences artificielles, retenir celles d’intérêt, et récupérer les fiches enrichies
Voici un premier aperçu de l’outil qui affiche les descriptifs d’images suggérés par une IA de vision par ordinateur, et permet de choisir les mots-clés les plus pertinents.
Utilisation d’API de classification de textes pour assigner des catégories BISAC ou Thema à des livres (deuxième partie)
Ce texte est le deuxième d’une série de deux décrivant notre démarche portant sur l’assignation automatique de catégories BISAC ou Thema depuis des textes de livres. Consultez d’abord le premier texte pour des explications.
Nous avons soumis une centaine de textes (les mêmes que nous avions utilisés pour notre expérience sur l’extraction de mots-clés) aux classificateurs personnalisés que nous avons bâtis avec TextRazor et Amazon Comprehend. Les résultats seront plus faciles à interpréter si on comprend bien la méthodologie qui a mené à la création de ces classificateurs.
Méthodologie d’entraînement des classificateurs
Amazon Comprehend
Le processus d’entraînement de Comprehend est relativement simple : il faut lui fournir un tableau dans lequel chaque ligne contient d’abord le code de classification, puis le texte correspondant. Nous avons constitué un tel tableau en procédant comme ceci :
- pour l’ensemble des titres de notre corpus, nous avons extrait les chapitres plus longs qu’une certaine taille déterminée (pour éliminer les « chapitres » EPUB à faible valeur sémantique)
- puis nous avons associé ces chapitres à chacun des codes BISAC qui avaient été assignés au titre par l’éditeur.
Donc, pour un livre placé dans 2 catégories BISAC par son éditeur, et dont 8 chapitres se qualifiaient, on a 16 (2 x 8) entrées dans le tableau d’entraînement.
Cela a produit un tableau à 117 121 lignes (provenant de 62 461 chapitres différents).
Nous avons choisi d’inclure toutes les données disponibles pour maximiser la taille de nos données d’entraînement (sachant que nous n’aurions pas le minimum suggéré d’environ 1000 textes par catégorie). Nous n’avons pas équilibré le nombre d’échantillons associé à chaque catégorie.
Une fois le tableau transféré dans Comprehend, puis « digéré » (au bout du processus « d’apprentissage », qui prend quelques heures), ce dernier est en mesure de suggérer trois catégories pour tout nouveau texte qui lui est soumis.
TextRazor
L’entraînement de TextRazor est fondamentalement différent sur les données, mais assez semblable sur la technique. Dans son cas, on doit créer un tableau où chaque ligne contient d’abord la catégorie, puis des mots-clés associés à cette catégorie. Dans notre cas, nous avons utilisé les termes du texte descriptif des catégories comme mots-clés. Ainsi, la ligne du tableau BISAC pour les livres de fiction sur les dragons contenait le code FIC009120 et les mots-clés « fiction fantasy dragons mythical creatures ».
Nous avons produit un tableau d’entraînement pour les codes BISAC (en anglais, puisque BISAC n’est disponible qu’en anglais) et les codes Thema francophones.
Une fois entraîné avec ces tableaux, TextRazor peut suggérer un nombre variable de catégories pour un texte (nos résultats vont d’aucune suggestion, jusqu’à dix).
Aperçu des résultats
L’ensemble des résultats de classifications ont été ajoutés aux données de l’expérience précédente sur les mots-clés.
Codes BISAC suggérés par Amazon Comprehend
Comprehend a suggéré 3 codes BISAC pour chaque texte. On constate rapidement toutefois que la majorité de ses suggestions sont des catégories très générales, par exemple « FIC00000 Fiction », ce qui n’ajoute pas à la richesse des classifications déjà identifiées par l’éditeur.
Il y a bien quelques exceptions intéressantes. Par exemple, pour Mathieu 06 — La Colère du roi, l’éditeur avait choisi « JUV000000 JUVENILE FICTION / General », et le classificateur suggère « JUV001000 JUVENILE FICTION / Action & Adventure / General » et « JUV028000 JUVENILE FICTION / Mysteries & Detective Stories », qui semblent pertinents au regard de la description du livre.
On voit également quelques cas où la catégorie suggérée est pertinente, mais peut-être trop précise. L’éditeur de La Science en 30 secondes avait choisi « SCI000000 SCIENCE / General », la catégorie générale pour la science. Le classificateur suggère en plus des sous-catégories plus précises : « SCI004000 SCIENCE / Astronomy » et « SCI075000 SCIENCE / Philosophy & Social Aspects (0,035) ». Considérant la description du livre, on peut deviner que ces thèmes sont également abordés, mais on peut également se demander si le sujet est suffisamment important pour assigner la catégorie au livre.
Cependant, hors quelques résultats intéressants, il y a de très nombreux exemples de suggestions génériques ou erronées.
Codes BISAC suggérés par TextRazor
Dans ce cas, il y a très peu de suggestions. Pour un grand nombre de textes, TextRazor n’a simplement pas émis de suggestion. Nous n’avons pas clairement identifié pourquoi (soit il ne trouvait rien, soit un problème technique non détecté l’empêchait de faire des suggestions, soit le fait d’entraîner avec des étiquettes en anglais puis d’appliquer le classificateur à des textes en français pose problème). Notons toutefois qu’il se reprend sur les cotes Thema (voir plus bas).
Ceci dit, parmi les résultats obtenus, certains sont encourageants. Pour La Construction du droit des Autochtones par la Cour suprême du Canada, l’éditeur avait choisi « LAW110000 LAW / Indigenous Peoples » et TextRazor suggère cinq autres catégories légales (« LAW011000 LAW / Civil Law », « LAW103000 LAW / Common », « LAW018000 LAW / Constitutional »…) qui semblent pertinentes.
Codes Thema suggérés par TextRazor
C’est ce classificateur qui génère les suggestions les plus nombreuses et en apparence les plus pertinentes.
Pour le livre Philippe H. dans l’angle mort dont la description parle de mythomanie et d’épisode psychotique, le classificateur suggère « JM Psychologie », « MKL Psychiatrie » et « JMP Psychopathologie » (ainsi que quelques autres catégories liées, mais en apparence moins pertinentes). Ou pour Félicité T3, il suggère « MBNK Vaccination », ce qui correspond bien à ce qu’on comprend de la description.
Par contre, il arrive souvent que les suggestions soient trop précises, comme « AVRL1 Guitare », « WGGB Bateaux », « AV Musique », « A Arts », « DC Poésie », « AVRL3 Violon » et « AVRG1 Piano », qui sont suggérés pour Passion Islande. On ne doute pas que tous ces thèmes soient mentionnés dans le texte, mais aucun n’est représentatif du texte dans son ensemble.
Dans tous les cas
Pour tous les classificateurs, il faut noter que les outils que nous utilisons, dans l’état actuel des choses, ne connaissent pas les règles associées à chaque système de classification, et ne sont pas en mesure de faire la nuance entre des catégories associées au type d’oeuvre (fiction ou pas) et des catégories « disciplinaires » (science, arts, droit, etc.). Ils ne savent pas non plus exploiter la hiérarchie des catégories (par exemple, dans Thema, AVRL3 correspond à Violon qui est un sous-thème de AV Musique, qui est un sous-thème d’A Arts).
Cela fait en sorte que leurs suggestions sont parfois strictement disciplinaires, même pour des oeuvres de fiction. Dans Thema, cela est « permis » si on assigne d’abord une catégorie de la famille F (Fiction); c’est moins clair pour BISAC.
Ceci dit, nous choisissons de ne pas tenir compte de ces nuances dans le contexte de cette expérience. On cherche à savoir si des classificateurs automatiques peuvent arriver à placer des textes dans des catégories, tout en sachant qu’une application industrielle de la solution demanderait un raffinement supplémentaire.
Analyse des résultats
Pour faire une analyse quantifiée des résultats, nous avons dû choisir une métrique qui permettrait d’évaluer la « performance » des suggestions, et sachant que sa mesure de pourrait pas être automatisée. En effet, dans les expériences typiques en apprentissage machine dont les résultats doivent appartenir à une seule catégorie, on réserve en général une partie des données dont on dispose pour mesurer la précision du classificateur. Dans notre cas, comme on souhaite générer des données supplémentaires, on ne peut pas les comparer avec les données d’origine.
Pour rendre la tâche possible, nous avons choisi de compter combien de classifications suggérées pouvaient être rejetées sur la seule base de la description du livre. Mesurer l’inverse, c’est à dire combien de classifications peuvent être retenues, demande une connaissance assez fine de chaque oeuvre (et on manquait de temps pour lire une centaine de bouquins!). Par contre, identifier qu’une catégorie « juvenile fiction » suggérée pour un roman érotique doit être rejetée est relativement simple.
Dans le cas des thèmes BISAC, nous avons également calculé la redondance des suggestions, c’est-à-dire le nombre de suggestions qui correspondaient à des classifications déjà identifiées par l’éditeur. Cette métrique est utile, mais doit être interprétée :
- si elle est basse, cela signifie que les classificateurs ne suggèrent pas souvent la ou les classifications assignées par l’éditeur (donc qu’ils ne reconnaissent pas bien les textes)
- si elle est élevée, cela signifie que les classificateurs n’amènent pas beaucoup de valeur, car ils suggèrent des classifications déjà identifiées.
Nous avons compilé les données à l’onglet Analyse de notre tableau de compilation des résultats des classificateurs.
Les valeurs moyennes obtenues pour chacune des métriques reflètent toutefois assez mal l’effet d’ensemble constaté lors de l’observation des suggestions pour chaque titre. C’est en segmentant les résultats par type de livre (fiction, fiction juvenile ou non-fiction) qu’on peut observer les tendances les plus intéressantes. On observe en particulier pour les textes de non-fiction :
- que TextRazor suggère significativement plus de catégories Thema sans pour autant augmenter le nombre de rejets
- c’est également le cas pour ses suggestions de catégories BISAC, quoique le nombre de suggestions soit faible
- qu’au contraire, pour Amazon Comprehend, les rejets sont plus élevés.
Conclusion
Au regard des résultats, il apparaît que les classificateurs que nous avons entraînés, dans l’état actuel des choses, ne seraient pas utilisables. Ils génèrent trop de bruit et pas assez de signal.
Cependant, l’approche demeure prometteuse. Malgré les problèmes relevés, il reste somme toute fascinant de constater qu’avec un entraînement de base, qui ne tient pas compte de la hiérarchie et des subtilités des systèmes de classification, on obtienne des résultats qui sont assez souvent bons ou presque bons.
Nous sommes donc convaincus qu’il serait possible d’arriver à des résultats significativement meilleurs en retravaillant nos données d’entraînement. En effet, en apprentissage machine, les données sont parfois aussi importantes (sinon plus) que les algorithmes. Dans notre cas, les données pourraient être mieux équilibrées (pour éviter les biais qui amènent Comprehend à suggérer les mêmes catégories à plusieurs reprises) et hiérarchisées (pour séparer les textes de fiction des autres avant d’établir les catégories « disciplinaires »).
