

Nous avons déjà expliqué pourquoi nous nous intéressons aux systèmes de classification dans un texte précédent. Et nous avons expliqué avoir obtenu des résultats intéressants, mais insuffisamment précis pour être utiles.
Après de nouveaux travaux, nous pensons être arrivés à une solution plus satisfaisante!
Ce texte explique comme nous y sommes arrivés et présente quelques résultats.
Rappel sur les classificateurs de textes
Pour comprendre notre démarche, il faut se rappeler comme fonctionnent les classificateurs de textes disponibles sur le marché. Sans s’attarder aux détails techniques et aux nuances, il faut comprendre que les classificateurs de textes en général «apprennent» à classifier à partir d’exemples. On fournit à un algorithme des milliers d’échantillons de textes, accompagnés de la catégorie à laquelle appartient le texte. L’algorithme «s’entraîne» à reconnaître de nouveaux textes, similaires à ceux des échantillons, et prédire dans quelle catégorie il doit le placer.
On peut illustrer le processus comme ceci:

C’est à l’algorithme de déterminer quels facteurs font qu’un texte doit être associé à telle ou telle catégorie. Il le fait essentiellement en établissant des corrélations statistiques entre des mots et des combinaisons de mots, et des catégories. Par exemple, les textes qui contiennent souvent «Bas Canada» et «Haut Canada» sont associés à la catégorie histoire (alors que «Canada» seul est peut être neutre et n’influence pas la catégorie). Ceux qui contiennent «Trudeau» et «Lévesque» sont plus susceptibles de traiter de politique; «influenza» et «appendice» sont des indicateurs de textes en médecine; etc.
Avec de très longs textes, les centaines de milliers de mots de la langue française, et près de 5000 catégories BISAC, on a du mal à imaginer la complexité des calculs statistiques nécessaires pour faire de bons classificateurs.
Les problèmes rencontrés précédemment
Les algorithmes de classification décrits précédemment sont évidemment influencés par la qualité et la quantité des données utilisées pour les entraîner.
Par exemple, si on ne donne en entraînement aucun texte dans la catégorie des biographies, l’algorithme ne pourra jamais identifier des biographies.
De la même façon, si on lui donne en grande majorité des textes classés comme une fiction (sans plus de précision), il fera en grande majorité des prédictions dans la catégorie fiction (…sans plus de précision!).
Notre première version de classificateur BISAC était affectée par ce problème. Les classifications dont nous disposons dans nos jeux de données ne sont pas nécessairement représentatives de ce qu’on veut voir dans nos résultats. On sait qu’on a beaucoup trop de livres classés dans la catégorie BISAC FIC000000 (la plus générale en fiction), on cherche à générer des classifications plus précises et plus riches.
Comment résoudre ce problème? Une approche est d’augmenter le nombre de textes disponibles pour l’entraînement, si on émet l’hypothèse que les nouveaux textes amènent de la diversité dans les catégories. Nous avons augmenté d’environ 25% le nombre de titres disponibles pour l’entraînement dans la nouvelle version de notre classificateur BISAC (essentiellement en traitant les fichiers PDF disponibles; nous avions utilisé les EPUB seulement dans la première version).
Un autre problème de la première version de notre classificateur était qu’il distinguait mal les textes de fiction des textes documentaires. Pour reprendre un des exemples précédents, un roman historique pourrait utiliser les termes «Bas Canada» et «Haut Canada» autant qu’un essai sur la politique à l’époque. Comme le classificateur ne connaît pas le système de classification, qui est hiérarchique (on distingue d’abord la fiction d’autres thèmes, puis à l’intérieur de chaque thème on a des sous-thèmes), il est très difficile pour lui de traiter ces cas.
Une nouvelle approche: on remplace le classificateur par des dizaines de classificateurs qui travaillent en équipe!
Nos travaux sur la nouvelle version du classificateur ont donc été réalisés pour atteindre deux objectifs:
- trouver une façon «d’aider» l’algorithme à comprendre la hiérarchie du système de classification ;
- ajuster la quantité de textes utilisés sur l’entraînement pour éviter de «surexposer» les algorithmes à certaines catégories.
Le résultat final est que le classificateur BISAC de TAMIS est en fait constitué d’une quarantaine de classificateurs spécialisés sur certaines «branches» de la hiérarchie BISAC. Ainsi, chaque texte est d’abord passé à un premier classificateur, qui sait distinguer les textes des catégories de premier niveau pour lesquelles nous avons un nombre suffisant d’échantillons.

Pour chaque catégorie, le classificateur indique la probabilité qu’elle s’applique au texte. Notre algorithme identifie les catégories les plus probables, trouve une classificate «spécialisé» pour chaque, et répète le processus.

Une fois le processus complété, un autre algorithme assemble les résultats, en pondérant les probabilités obtenues de chaque classificateur spécialisé, et arrive à une suggestion de 3 à 5 codes BISAC. Dans certains cas, si la probabilité obtenue de tous les classificateurs est trop faible, aucune suggestion n’est faite.
Note sur la technologie de classification utilisée
Pour nos lecteurs intéressés par les questions de développement logiciel… les autres peuvent passer à la section suivante!
Lors de nos premiers tests, nous avions retenu la solution Comprehend d’AWS pour faire les classification. Cette solution était la seule qui répondait à nos besoins lors de nos travaux il y a quelques mois.
Il s’est toutefois avéré qu’elle n’était pas adaptée à notre nouveau besoin. Nous avons rencontré plusieurs contraintes lors du passage de la recherche au développement. En particulier, la limite sur le nombre de classificateurs personnalisés actifs dans un compte AWS, et le fait que les opérations de classification ne puissent être opérées qu’en lot dans un traitement différé en arrière plan. Cela rendait impossible d’utiliser notre stratégie.
Nous nous sommes alors tournés vers la solution AutoML Natural Language dans Google Cloud. Nous l’avions écartée précédemment parce que c’est un produit toujours en phase «beta» et la gestion du français n’est pas garantie. Malgré cela, les résultats sont impressionnants, et les contraintes d’utilisation sont moins grandes. Nous avons quand même été limités par un quota sur le nombre de classificateurs actifs. Aussi, bien que les opérations de classification soient réalisées en direct (et pas en traitement différé) dans des délais relativement courts, il reste que la performance n’est pas encore instantanée (il peut parfois s’écouler 3 à 5 secondes avant qu’un utilisateur de la console n’obtienne les résultats).
Les résultats
Nous observons de façon générale que les classifications proposées sont plus riches et plus diversifiées. C’était ce qu’on souhaitait.
Pour un livre sur l’histoire des patriotes, l’algorithme propose la catégorie «Political science». Pour le coffret 1967, l’éditeur avait choisi la catégorie «Fiction», l’algorithme propose «Fiction / Sagas» (c’est effectivement une saga!). Pour la biographie de Normand Brathwaite, il propose la catégorie «Performing arts».
Évidemment, comme dans la plupart de nos expériences, nous obtenons également des résultats farfelus ou impertinents. Toutefois, ces suggestions moins intéressantes sont souvent accompagnées d’une cote de «confiance» (nous y reviendrons plus loin) assez faible.
Il arrive aussi que l’algorithme ne propose que des catégories BISAC que l’éditeur avait déjà identifiées… Ça démontre sa précision, bien sûr, mais n’atteint pas nos objectifs d’enrichir les métadonnées. Cela est plus fréquent chez les éditeurs qui indiquent plusieurs catégories (et ont donc vraisemblablement déjà des métadonnées assez riches sur le plan des classifications).
L’utilisation dans la console
Concrètement, dans la console de l’éditeur, une page permet, pour chaque livre, d’obtenir les suggestions. Elle prend la forme suivante:
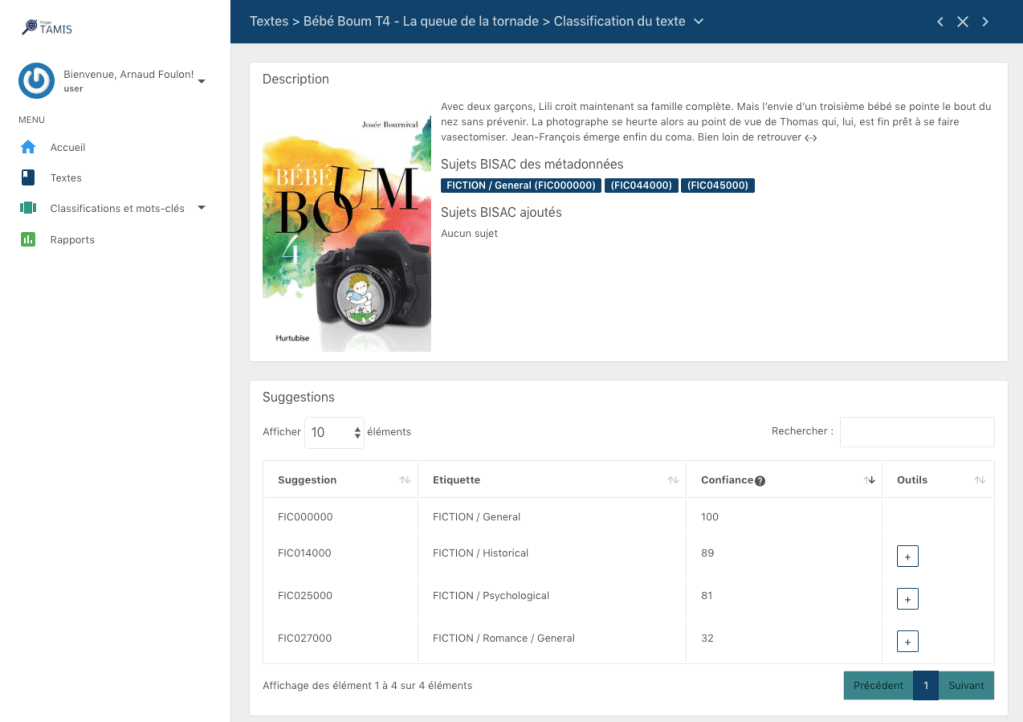
Dans le haut, on voit les métadonnées que l’éditeur avait documentées. Dans le bas, les suggestions de l’algorithme. Pour les suggestions qui n’avaient pas déjà été choisies par l’éditeur, le bouton «+» permet de confirmer et de l’ajouter aux métadonnées.
Chaque suggestion est accompagnée d’un indicateur de «confiance». Il s’agit d’un nombre, entre 0 et 100, qui donne une approximation du niveau de pertinence de la suggestion, selon l’algorithme. Un nombre élevé indique qu’il est probable que la suggestion soit pertinente.
Conclusion
Cette nouvelle version de notre classificateur BISAC n’est certe pas parfaite, mais elle résout plusieurs des problèmes de la version précédente. Son développement a présenté plusieurs défis techniques qui ne sont qu’évoqués superficiellement ici. Nous croyons que les résultats améliorés justifient les efforts.

Ping : Une nouvelle technologie de classification pour l’outil de suggestions de code BISAC de TAMIS – Projet TAMIS