

Le développement de Tamis est entré récemment dans une nouvelle phase, encore plus excitante que les précédentes.
En effet, après avoir appris à utiliser divers algorithmes pour analyser les couvertures et les textes de livres et en extraire divers éléments utiles pour les décrire, nous avons commencé à utiliser également ces données dans le but de permettre de nouveaux types de recherche et d’analyse de l’ensemble des livres qui ont été mis à notre disposition.
Nous souhaitons, par exemple, être en mesure d’identifier tous les livres dont l’action se déroule à proximité de la Rivière Saint-Charles — et même les passages précis où l’action s’y déroule! Autre exemple: identifier les livres écrits par des femmes qui sont nées dans la région de Québec avant 1950. Ou encore les livres publiés par des maisons d’édition de Québec dont l’auteur, ou l’autrice, est née à l’étranger.
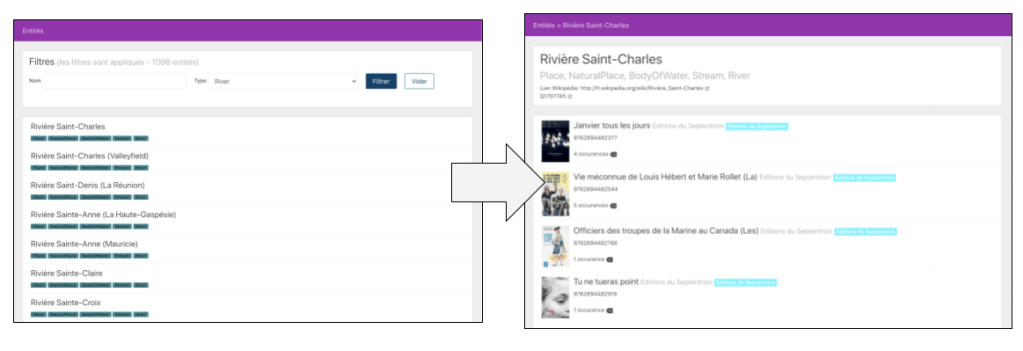
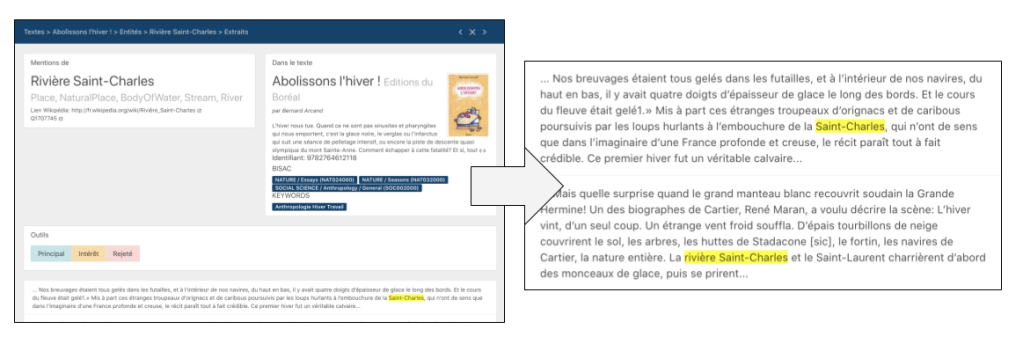
Nous voulons évidemment pouvoir faire aussi l’inverse: partir d’un livre et explorer, visuellement, sur une carte, tous les lieux qui sont évoqués; ou les événements historiques auxquels il est fait référence; ou encore les aliments, les groupes musicaux, les planètes, les éléments chimiques, etc.
Pour arriver à répondre à ces questions, nous avons besoin de pouvoir lier les données que les algorithmes de Tamis nous ont permis d’extraire avec des données qui se trouvent dans d’autres bases de données — et en tout premier lieu, avec les données que Wikidata met à notre disposition.
Mais avant d’aller plus loin… prenons le temps d’explorer, sommairement, ce qu’est Wikidata et pourquoi cette base de données est en train de prendre une importance croissante dans l’organisation de l’information sur le Web (et même beaucoup plus largement).
Wikidata? Vous voulez dire Wikipédia?
Tout le monde connaît maintenant Wikipédia — une des projets les plus ambitieux de l’ère numérique: une encyclopédie universelle, multilingue, à laquelle tout le monde peut contribuer. Il y a vingt ans, bien des gens disaient que « ça ne pourrait pas marcher, parce que si tout le monde pouvait modifier le contenu, ce serait forcément un peu n’importe quoi ». Pourtant, la suite montre que ça fonctionne, et que Wikipédia est devenue une source d’information de qualité, fiable… et de plus en plus indispensable!
Wikidata, c’est un peu la même chose, mais à l’intention des machines: c’est une base de données de référence sur tous les sujets, que tout le monde peut modifier, et où l’information est rassemblée de manière à pouvoir être utilisée dans le cadre de processus automatisés (algorithmes) plutôt que pour être consultée par des êtres humains. Pas de mise en page, pas de phrases complètes, juste des informations factuelles, présentées de façon normalisée et organisée de façon structurée.
Wikidata indique, par exemple, que Jean-Paul L’Allier est un être humain (rien d’évident là pour un algorithme 0 il est donc pertinent de le préciser!), de sexe masculin, qu’il a un lieu de naissance, quelles ont été ses principales occupations qu’il a exercées, les reconnaissances qui lui ont été accordées, etc. — ainsi qu’une série d’identifiants qui permettent d’aller chercher de l’information complémentaire à son sujet dans d’autres sources de données.
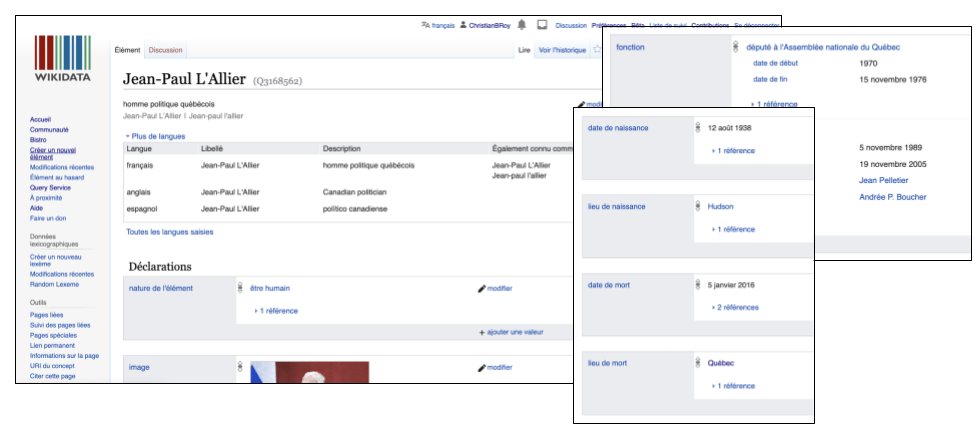
C’est comme ça que si on possède une base de données d’auteurs et d’autrices, par exemple, et qu’on a pris la peine d’y noter, pour chacun, son identifiant dans Wikidata (qu’on peut voir dans le haut de la page, sur Wikidata: Q3168562, dans le cas de Jean-Paul L’Allier), on pourra assez facilement programmer un petit algorithme pour aller chercher dans Wikidata une foule d’autres informations sur chacun des auteurs et des autrices afin de compléter notre base de données.
La magie des liens
Mais là où la magie opère vraiment, c’est que l’information dans Wikidata est organisée de façon sémantique, toutes les entités sont liées les unes avec les autres. Ce qui permet d’aller beaucoup plus loin que de simplement additionner des informations d’une base de données à l’autre. Parce que la latitude et la longitude d’un lieu sont associées à une ville, à une région, un pays; parce qu’une rivière est associée à ses affluents; parce que les années sont associées à une période historique, etc.
C’est en suivant ces liens d’une donnée à l’autre qu’on peut savoir qu’un livre qui fait référence au Pont Drouin peut aussi être associé à la Rivière Saint-Charles; qu’un récit qui fait référence à l’usine WhiteBirch, à Québec, est non seulement près de la même rivière, mais qu’il se déroule forcément entre telle année et telle année, etc.
Concrètement, en associant un lieu de naissance à des auteurs et autrice dans Wikidata, et sachant que ces lieux sont à leur tour associés à des régions, auxquelles sont associées des coordonnées géographiques… il devient possible d’identifier tous les auteurs et les autrices sont nées au nord du 45e parallèle, par exemple. Ou de savoir combien d’auteurs d’une maison d’édition ont aussi travaillé à la réalisation d’un film, en s’appuyant sur les identifiants qui relient Wikidata à IMDB, une base de données spécialisée sur le cinéma.
Ce n’est évidemment pas sans raison que Google, Microsoft, Facebook, Amazon, etc. utilisent abondamment les données de Wikidata. C’est parce qu’ils croient qu’elles sont utiles pour rejoindre plus efficacement leurs usagers, pour leur offrir de meilleurs résultats de recherches et de meilleures recommandations.
Des opportunités pour améliorer la commercialisation du livre
Cela révèle deux opportunités pour le monde du livre: apprendre à utiliser nous aussi les données ouvertes et liées (comme celles de Wikidata) et enrichir ces données de celles qui concernent les livres publiés ici, pour les rendre plus facilement découvrables, dans toutes sortes de contextes.
Que ce soit pour répondre à des objectifs très précis, comme améliorer le référencement d’un livre sur un sujet pointu, ou tout «simplement» pour faire en sorte qu’Alexa, Siri et leurs collègues connaissent la littérature d’ici, il est essentiel de saisir ces opportunités.
C’est à ce double défi que nous nous attaquons maintenant avec Tamis. Nous le faisons en collaboration avec l’Institut canadien de Québec, dans le cadre d’un projet qui s’inscrit dans la perspective de Québec, ville de littérature de l’UNESCO. Un projet qui est soutenu par le programme Exploration et déploiement numérique du Conseil des Arts et des Lettres du Québec (CALQ).
Avant de commencer le travail, nous avons tenté de tracer un premier portrait préliminaire de la présence des auteurs et autrices et romans de Québec (et du Québec) sur Wikidata.
Ce sera le sujet du prochain texte.

Ping : Robibase et Tamis – Projet TAMIS
Ping : Robibase et Tamis – Jeux de mots et d’images
Ping : Nouveautés 2021 dans TAMIS – Projet TAMIS